日曜日とhubotとGithub
hubotを育てていた日曜日だった。
hubotとは、Github社が開発して、チャットbot開発・実行フレームワークのことです。 モダンな開発環境を構築している企業等々様々なところで利用されています。
HipChatやSlackやChatWorkとの連携も簡単にできる!
日曜日にやっていたことは、
hubot pullreq <repository> base <base_branch> compare <head_branch> title <title>
ってhubotに言えば、Github上でpullreqを作ってくれるやつを作った。
それを実現した流れを以下に書きますー。
Macのローカル環境下で試してみたよ。
curl -i https://api.github.com/authorizations -d '{"note":"hubot_local_test","scopes":["repo"]}' -u "yourgithubaccount"
これで
{
"id": xxxxxx,
"url": "https://api.github.com/authorizations/cccccc",
"app": {
"name": "hubot local (API)",
"url": "https://developer.github.com/v3/oauth_authorizations/",
"client_id": "00000000000000000000"
},
"token": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"note": "hubot local",
"note_url": null,
"created_at": "2014-06-28T11:06:43Z",
"updated_at": "2014-06-28T11:06:43Z",
"scopes": [
"repo"
]
}
が返ってくるから、これのtokenをコピーして
export HUBOT_GITHUB_TOKEN="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
する。
hubotの導入等々はこちらで。
http://qiita.com/kmdsbng/items/fdc069048b5f0d07295e
scripts/github.coffee
# Description: # Githubに関連するhubotスクリプト # # Commands: # hubot pullreq <repository> base <base_branch> compare <head_branch> title <title> module.exports = (robot) -> github = require('githubot') url_api_base = "https://api.github.com" robot.respond /pullreq\s+for\s+(.*)\s+base\s+(.*)\s+compare\s+(.*)\s+title\s+(.*)/i, (msg)-> repo = github.qualified_repo msg.match[1] base_branch = msg.match[2] head_branch = msg.match[3] title = msg.match[4] data = { title: title, head: head_branch, base: base_branch } url = "#{url_api_base}/repos/#{repo}/pulls" github.post url, data, (pullreq) -> msg.send pullreq.html_url
ちょっとだけ解説を入れますと
repo = github.qualified_repo msg.match[1]
このように書くと
msg.matchに入っているのが
testとかだと、kohey18/testに変換してくれる。
ちょっとテンションあがって
hubot show <assignee> issues for <repository>
ってコマンドでそのレポジトリに対応する自分のassignされたIssueが出るのも作ってみました。 またどこかで公開します。
- 書き方はこの辺参照
https://github.com/github/hubot-scripts/blob/master/src/scripts/github-issues.coffee
- githubotのpackage
https://github.com/iangreenleaf/githubot
今週も頑張りましょう!
nginx + mrubyで画像返すやつ書いてみた
(おい!またこいつnginxの話してるぞ!!)
わりと環境構築から詰まるところ多かった
matsumoto-r/ngx_mruby · GitHub
基本的にここ参照だお!
git clone git://github.com/matsumoto-r/ngx_mruby.git cd ngx_mruby git submodule init git submodule update sh build.sh sudo make install
github上のREADMEに
./configure --prefix=/usr/local/nginx --add-module=${NGX_MRUBY_SRC} --add-module=${NGX_MRUBY_SRC}/dependence/ngx_devel_kit --add-module=${SOME_OTHER_MODULE}
みたいな感じでいける! って書いてあって、nginxのコンパイルみたいなのいつもconfigure使ってたし、configureでやろうと思ったら、
--add-moduleとかないお!
とか言われて、--helpとかで見たらそんなオプションなかったw
素直に、ビルドするためのスクリプト用意してくれてるので、それ使ったらいいと思います。
rakeコマンド使えるようにしていない人は
gem install rake
しとけば、いけるはず。
あとhiredis周りでエラー吐くかも。
Macなら
brew instlal hiredis
CentOS上なら
git clone https://github.com/redis/hiredis.git cd hiredis make && sudo make install
でいけたはず。
一回詰まったんはhiredisのバージョンがおかしいって言われ続けた気がする。
最初、hiredisの設定するのに、
sudo yum install hiredis-devel hiredis
でやったら、バージョン1個古くて、動かんかった。(ここクッソ詰まった)
0.11?をビルドするようにすればいいと思います。
0.11にバージョンできて、ngx_mrubyの見てるバージョンが違っているのも詰まった。
そんときは
先にhiredisの構築してから、ngx_mrubyのビルドスクリプト回せばおk
nginx + mrubyのどこがええの?
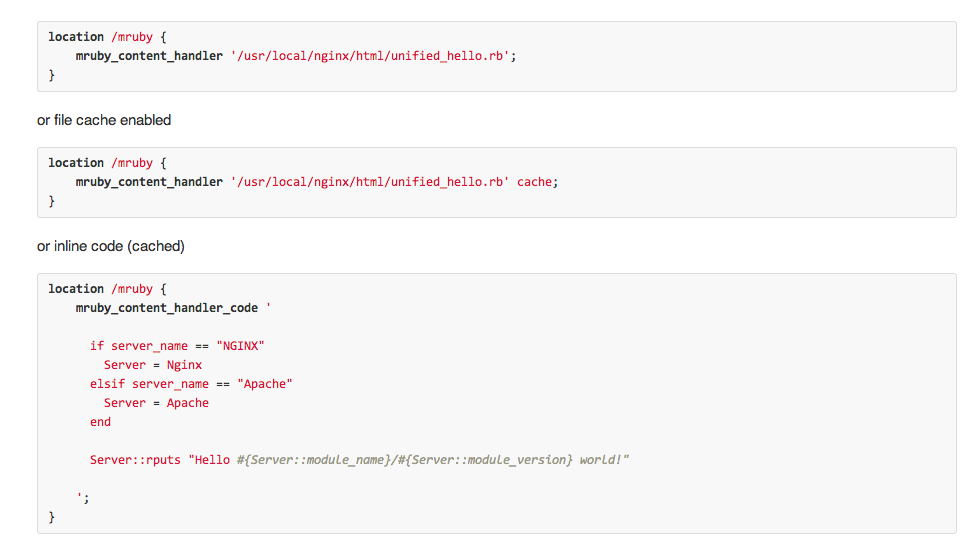
こんな感じで、nginx.confにrubyスクリプト埋め込めたり、rubyスクリプトを外部から呼んだりして、nginxの変数を変更したりとか。
とりあえず、静的ファイルである画像を返すのをnginx+ mruby使えばこんな感じになる
location ~ /(.*\.png) {
set $image_name $1;
set $image_path "";
add_header Content-type image/png;
mruby_access_handler /usr/local/ngx_mruby/build/nginx/html/get_image.rb;
root $image_path;
}
/usr/local/nginx_mruby/build/nginx/html/get_image.rb
r = Nginx::Request.new s = Nginx::Server.new image_name = r.var.image_name first_dir = r.var.image_name[0,1] second_dir = r.var.image_name[1,1] filename = "/home/koheyhey/localdata/#{first_dir}/#{second_dir}/#{image_name}" r.var.set "image_path", filename
r.var.image_name
で、nginxの変数を取得している。
nginx.conf内に
set $image_name $1;
って書いたこれをrubyスクリプト内で取得できるみたいな感じ。
nginx.conf上だと文字列分割とかその辺の処理書くの面倒(正規表現ゴリゴリに書いたらいける)
mrubyとかなら、 外部で呼び込んだrubyスクリプト内でゴリゴリnginxの変数をrubyで書けるよね!ってところが便利だね!ってことか。
r.var.set "image_path", filename
とかだと、nginx.conf内で初期化しておいた
set $image_path "";
を新たにsetする感じ。
今回は外部のrubyスクリプトファイルを呼んでるみたいな感じで書いたけど、
nginx.conf内でもrubyスクリプトゴリゴリ書くこともできる。(数行ならこれでもエエと思う)
あと、わりと詰まったところは
mruby_access_handler '/home/ec2-user/get_image.rb' cache;
このmruby_access_handlerの後ろにcacheを付けへんと動かない事案発生してた(EC2上)
ローカルだとそんなことなかった。
そんなことより、このレポジトリの人、京大の博士課程っぽいから一回会ってみたい。
今回はここまで。
nginx+luaで画像返すやつ書いてみた。
nginxのLuaモジュール使ってみた。
OpenResty - a fast web app server by extending nginx
nginxにLuaモジュール組み込むのにコレ使った。
インストール方法
wget http://openresty.org/download/ngx_openresty-1.5.11.1.tar.gz cd ngx_openresty-1.5.11.1.tar.gz tar xvfz ngx_openresty-1.5.11.1.tar.gz cd ngx_openresty-1.5.11.1 ./configure --with-luajit gmake sudo gmake install
この辺でうまくいく。(EC2上だと)
Macだと普通にmakeコマンドとmake installコマンドでおk。
起動方法
/usr/local/openresty/nginx/sbin/nginx
再起動
/usr/local/openresty/nginx/sbin/nginx -s reload
停止
/usr/local/openresty/nginx/sbin/nginx -s stop
confファイル設定
emacs /usr/local/openresty/nginx/conf/nginx.conf
nginx.confの追加部分
server {
listen 8081;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location ~ /(.*\.png) {
set $image_path $1;
content_by_lua_file /usr/local/openresty/lualib/send_image.lua;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
content_by_lua_fileでresponseを生成するコードを実行する
参照スライド
Using ngx_lua / lua-nginx-module in pixiv
/usr/local/openresty/lualib/send_image.lua
nginx.confで
set $image_path $1
って書いているのは、正規表現でlocalhost:8081/hoge.pngで$image_pathにhoge.pngが入るように。
そうすると
local image_path = ngx.var.image_path
でluaスクリプト内にnginxで読んだ値をluaスクリプト内で変数格納できたよー!って感じかな。
結構詰まってたのは
local file = io.open(source_fname,"r") ngx.say(file)
で画像返そうと思ったら、うまくいかなかった。
readオプションつけてるし、うまくいくと思ったらダメだった。
local file = io.open(source_fname)
input_file_stream = file:read("*a")
ngx.say(input_file_stream)
file:readを一回かましたら行けた。
さて、これのベンチマーク取りますかー。
http_loadでベンチマークしてた一日だった
abコマンドは
Apacheのabコマンドでベンチマークを測定する | Linuxで自宅サーバ構築
こんな感じでやったことあったけど、先輩に今日はhttp_load教えてもらった。
http://www.acme.com/software/http_load/
wget http://www.acme.com/software/http_load/http_load-12mar2006.tar.gz tar xvfz http_load-12mar2006.tar.gz cd http_load-12mar2006 make
gccないって怒られた
sudo yum install gcc make make install
なんかエラー吐いた
mkdir /usr/local/man/ mkdir /usr/local/man/man1 make install
これでhttp_loadコマンド打てた。
abコマンドとの違いを調べると
複数のURLに対して同時にhttpアクセスできる
ってのが売りらしい。
/home/ec2-user/sample.txt
http://hoge.com/sample.png http://hoge.com/sample.png http://hogepiyo.com/sample.png http://hogehoge.com/sample.png http://hogepiyopiyo.com/sample.png
こんな感じでテキストにベンチマークしたい先のURLを書いておく。 複数のURLがあることがここでわかる。
あとはこんな感じでコマンド打つ
http_load -parallel 150 -seconds 10 sample.txt
parallelが同時接続数 secondsが接続する秒数
レスポンスはこんな感じ。
4184 fetches, 110 max parallel, 4.66704e+08 bytes, in 10 seconds 111545 mean bytes/connection 418.4 fetches/sec, 4.66704e+07 bytes/sec msecs/connect: 46.8614 mean, 95.575 max, 0.831 min msecs/first-response: 81.2267 mean, 217.853 max, 3.516 min HTTP response codes: code 200 -- 4184
node.jsでContent-Type指定する際のメモ
ただ、リクエストに対して、ただ、画像を返すやつ書いてたのに、一瞬詰まった。
var express = require('express'); var router = express.Router(); var fs = require('fs'); /* GET images listing. */ router.get('/', function(req, res) { image_path = req.originalUrl.slice(1); var buf = fs.readFileSync(image_path); res.send(buf, { 'Content-Type': 'image/png' }, 200); }); module.exports = router;
localhost:3000/123456abcabc3333123456abcabc3333.png
で画像返ってくると思ったら、なんか画像返らんと、ダウンロードされて「は?」ってなった。
WebConsole見てもContent-Typeが'image/png'にならなくて詰んでた。
これが正解
var express = require('express'); var router = express.Router(); var fs = require('fs'); /* GET images listing. */ router.get('/', function(req, res) { image_path = req.originalUrl.slice(1); var buf = fs.readFileSync(image_path); res.writeHead(200, {'Content-Type': 'image/png' }); res.end(buf); }); module.exports = router;
非同期的に書くと
var express = require('express'); var router = express.Router(); var fs = require('fs'); /* GET images listing. */ router.get('/', function(req, res) { image_path = req.originalUrl.slice(1); fs.readFile(image_path, function(err,file){ res.writeHead(200, {'Content-Type': 'image/png' }); res.end(file); } ); }); module.exports = router;
もちろんapp.jsに
var images = require('./routes/images'); app.use('/([0-9a-f]{32}).png',images);
は書いてるよー
それ前提の話ね。
半日、ベンチマークしてた。
Rubyでcurlした時のメモ
最近、Ruby系の記事多いけど、
初心者すぎ、かつ、バイト等で仕事に応じてPythonとPHPとか 言語変わるから、
Rubyに関してはいまだに
ruby 配列 長さ
とかでググってまうw
lengthやっけ?sizeやっけ?countやっけ?
とかパニックになるときあるんで。
Rubyでcurl
open-uri
net/http
とかいろいろあるけど、open-uriはGETしか使えなさそうなので、net/httpでcurlの処理書いてみます。
ベース
# -*- coding: utf-8 -*- require 'net/http' # curlのタイムアウト設定 time_out = 30 uri = URI.parse("http://hogepiyoheyhey.com") Net::HTTP.start(uri.host, uri.port){|http| #リクエストインスタンス生成 request = Net::HTTP::Post.new(uri.path) request["user-agent"] = "Ruby/#{RUBY_VERSION} MyHttpClient" request.set_form_data("uid"=>123456) #time out http.open_timeout = time_out http.read_timeout = time_out #送信 response = http.request(request) p "====RESULT(#{uri.host})========" p "==> "+response.body }
basic認証が入ったパターン
# -*- coding: utf-8 -*- require 'net/http' # curlのタイムアウト設定 time_out = 30 uri = URI.parse("http://hogepiyoheyhey.com") Net::HTTP.start(uri.host, uri.port){|http| #リクエストインスタンス生成 request = Net::HTTP::Post.new(uri.path) request["user-agent"] = "Ruby/#{RUBY_VERSION} MyHttpClient" request.set_form_data({"uid"=>"hogehoge"}) #time out http.open_timeout = time_out http.read_timeout = time_out #=====ここ追加====== #user auth request.basic_auth 'hogehoge','piyopiyo' #送信 response = http.request(request) p "====RESULT(#{uri.host})========" p "==> "+response.body }
httpsを使った場合
# -*- coding: utf-8 -*- require 'net/https' uri = URI.parse("https://hogepiyoheyhey.com") https = Net::HTTP.new(uri.host,uri.port) #httpsだとこれ必要 https.use_ssl = true #use_ssl value changed, but session already started (IOError) #にならないように、sslをONにしてから、request生成 request = Net::HTTP::Post.new(uri.path) request.set_form_data({"uid"=>"hogehoge"}) res = https.request(request) p res.body
ちょっと書き方変えたの気づきました?
上記の「ベースパターン」を利用すると
Net::HTTP.start(uri.host, uri.port){|http| request = Net::HTTP::Post.new(uri.path) https.use_ssl = true }
とコールバックっぽく書いてたけど、httpsやとこのやり方やとエラー吐いてた。
use_ssl value changed, but session already started (IOError)
とか怒られた。
uri = URI.parse("https://hogepiyoheyhey.com") https = Net::HTTP.new(uri.host,uri.port) #httpsだと先にこれを書く https.use_ssl = true #use_sslをtrueにした状態でPOSTするよ!って感じで書く request = Net::HTTP::Post.new(uri.path)
これでうまく行った。
他にいい方法はあるのだろうかー。
ちなみにですが、PHPだと
<?php $time_out = 30; $hoge = array( "uid"=>32, "name" => "Heyheyhey", ); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "http://hogepiyohey.com"); curl_setopt($ch, CURLOPT_POST, TRUE); curl_setopt($ch,CURLOPT_RETURNTRANSFER,TRUE); curl_setopt($ch, CURLOPT_POSTFIELDS, $hoge); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $time_out); curl_setopt($ch, CURLOPT_TIMEOUT, $time_out); //Basic認証の際はこちら curl_setopt($ch, CURLOPT_HTTPAUTH, CURLAUTH_BASIC ) ; curl_setopt($ch, CURLOPT_USERPWD, "hogehoge:piyopiyo"); print "====RESULT========\n"; print "=>\n"; print curl_exec($ch); print "\n=========================================\n\n"; curl_close($ch); ?>
PHP落ち着くわーwww
SinatraとかUnicornとか
Sinatraの業務が出来たので、ちょっとメモしておく。
ってか、初Rubyやったね!
UnicornとかPassengerは聞いたことある!
Sinatra
nginxとunicorn
・参考文献
[nginx]
upstream app1 {
server unix:/tmp/app1.sock;
}
server {
listen 3001;
server_name localhost;
location / {
root /SinatraProduct/public;
proxy_pass http://app1;
proxy_set_header Host $host;
}
}
[unicorn.rb]
# -*- coding: utf-8 -*- # unicorn.rb # coding: utf-8 # プロジェクトディレクトリへのパス @path = "/SinatraProduct/" worker_processes 1 # CPUのコア数に揃える working_directory @path timeout 300 listen '/tmp/app1.sock' # Nginxのconfig内にあるupstreamで、このパスを指定 pid "#{@path}tmp/pids/unicorn.pid" # pidを保存するファイル # logを保存するファイル stderr_path "#{@path}log/unicorn.stderr.log" stdout_path "#{@path}log/unicorn.stdout.log" preload_app true
nginx
sudo nginx #起動 sudo nginx -s stop #停止
Unicorn
bundle exec unicorn -c unicorn.rb -D #-Dでデーモン化
これでlocalhost:3001で見れるはず
Erbテンプレートを使う
[Gemfile]
gem install bundler cd project bundle init #Gemfileが生成される
入れたいgemをGemfileに書く
source "https://rubygems.org" gem 'sinatra' gem 'haml' gem 'mysql2' gem 'activerecord' gem 'unicorn'
gem関連インストール
bundle install --path vendor/bundle
erbテンプレートの追加
[Gemfile]
gem 'erb'
[views/index.html.erb]
require 'erb'
get '/' do
erb :index.html
end
エラー関連
unicorn + nginxで502
unicornの起動側でエラーはいているっぽいから logを見てあげれば良い
emacs DocumentRoot/log/unicorn.stderr.log
DocumentRoot/vendor/bundle/ruby/2.0.0/gems/unicorn-4.7.0/lib/unicorn/configurator.rb:91:in `block in reload': directory for pid=DocumentRoot/tmp/pids/unicorn.pid not writable (ArgumentError)
[答え] ちゃんとディレクトリ掘れてるかチェックしろカス